
Background
뉴스 서비스는 시의성이 중요합니다. 그래서 팀원들에게 공유하는 시안도 계속 새로운 데이터로 채워지면 좋겠다는 생각이 들었습니다. 그렇다고 작업할 때마다 기사를 하나하나 옮겨서 타이핑하는 것은 귀찮았기 때문에 활용할 수 있는 도구들을 찾아 최대한 활용해보기로 했습니다.
Tools
Figma(피그마), Google sheet sync(피그마 플러그인), Python(파이썬)
Figma setting

우선 어떤 데이터가 필요한지 정하고, Figma 에서 컴포넌트 안의 레이어 이름을 지정합니다. 레이어 이름 앞에 ‘#’을 붙여주면 됩니다. 저는 Auto layout 기능을 같이 활용했습니다.
Google sheet
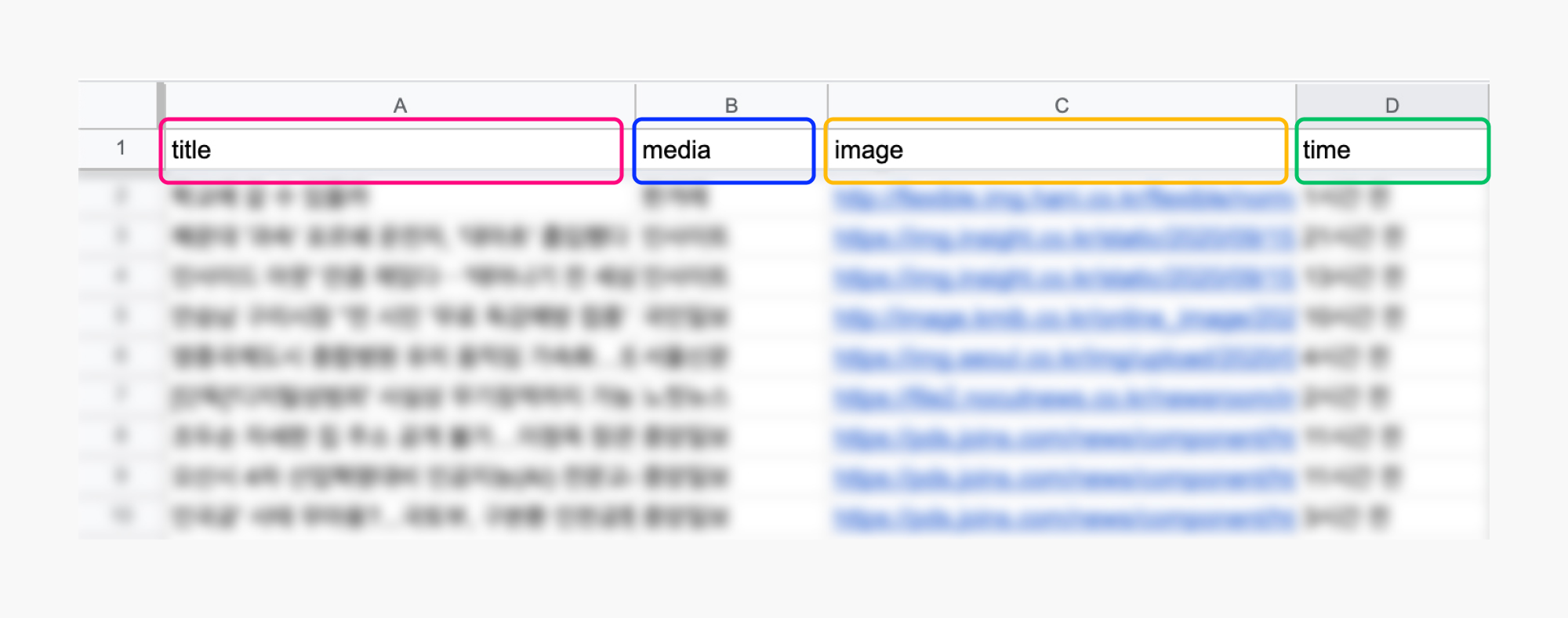
위에서 지정한 레이어 이름을 Google sheet에서 첫번째 행 데이터로 지정하고, 하단에 데이터를 채웁니다. 이미지의 경우 이미지 url을 기입하면 됩니다. 이 시트의 데이터는 앱에서 사용하고 있는 API를 통해 가져왔는데요, 데이터를 가져온 방법은 아래쪽에서 더 자세하게 다룰게요.
Google sheet sync (Figma Plugin)
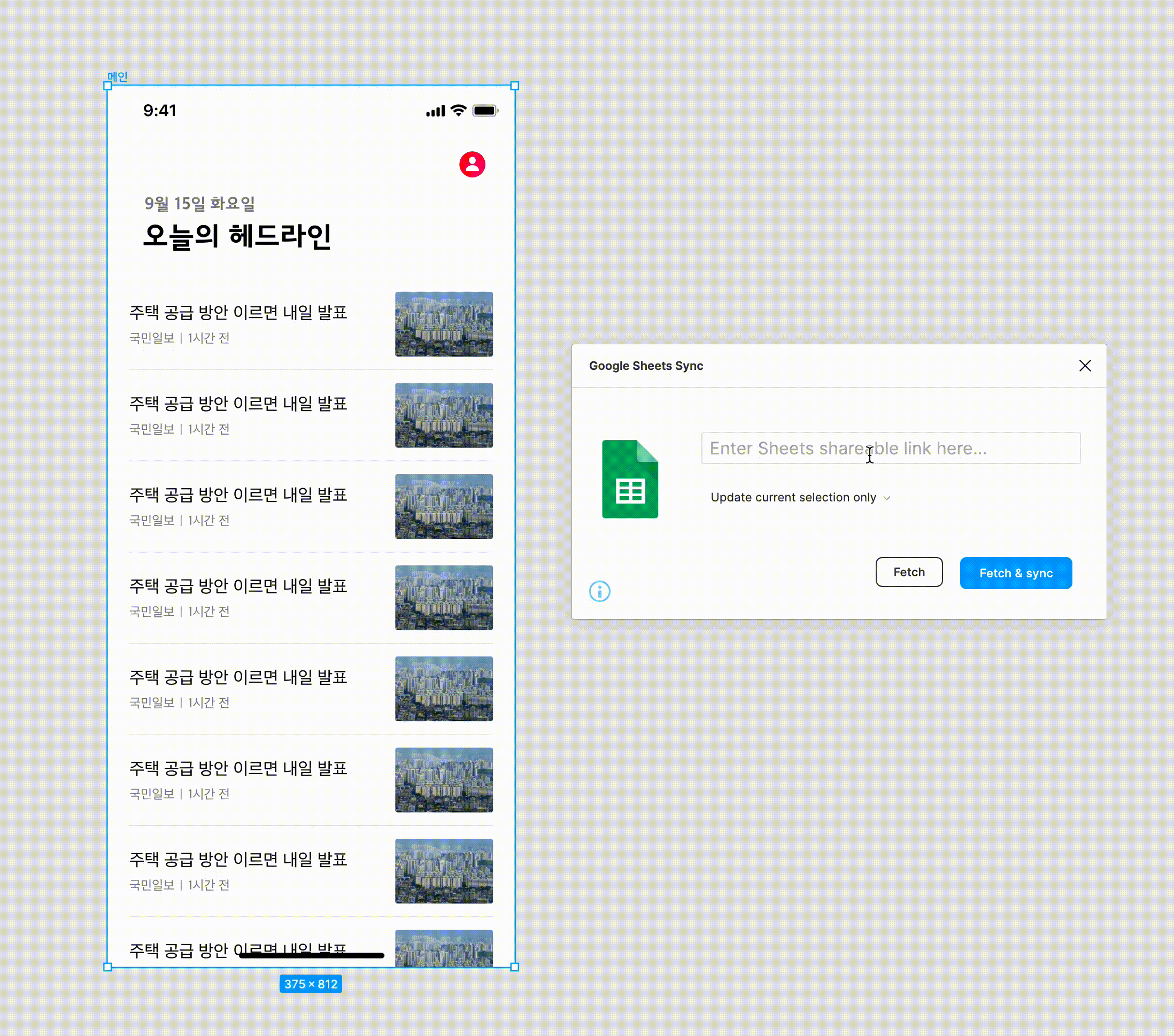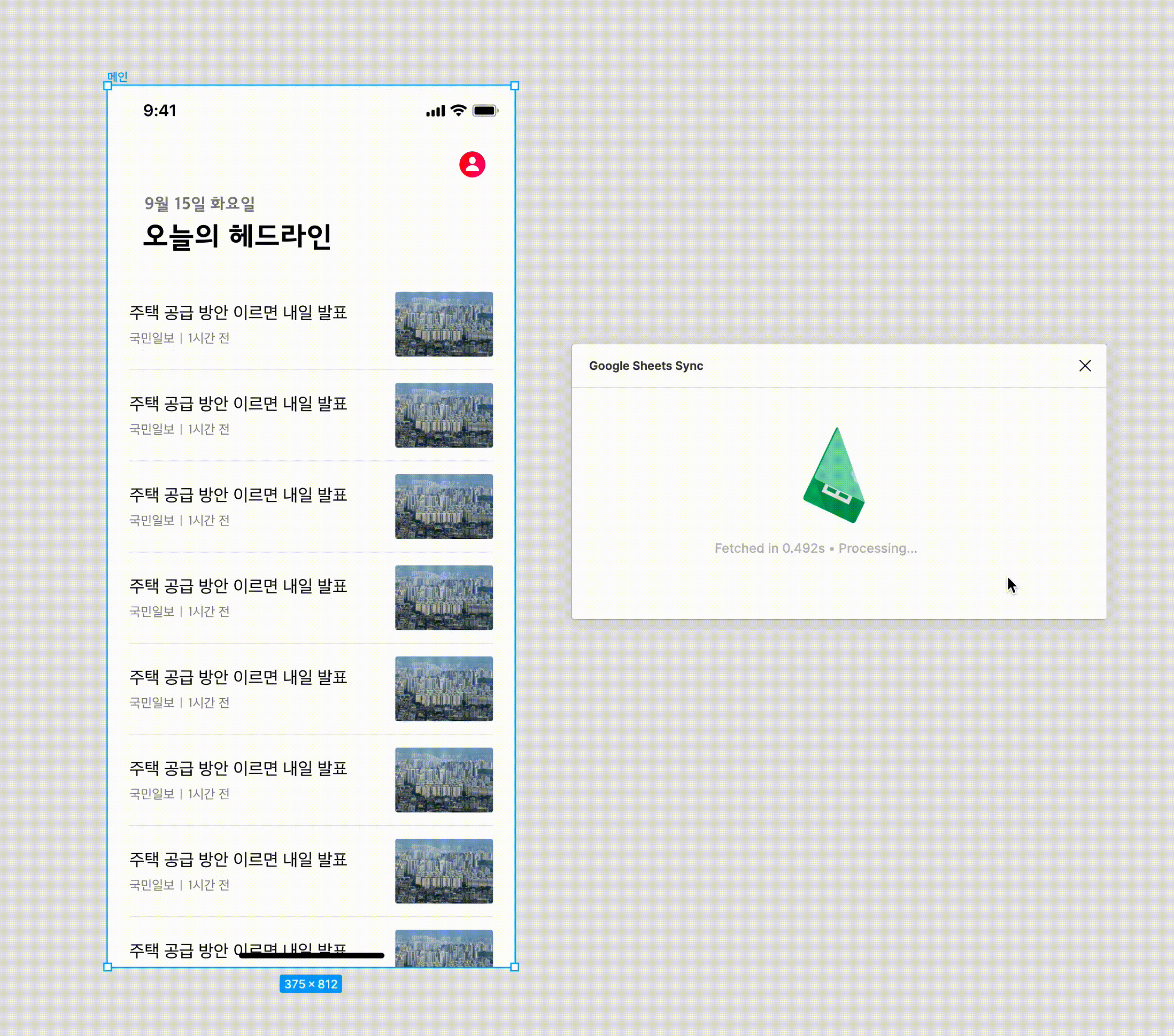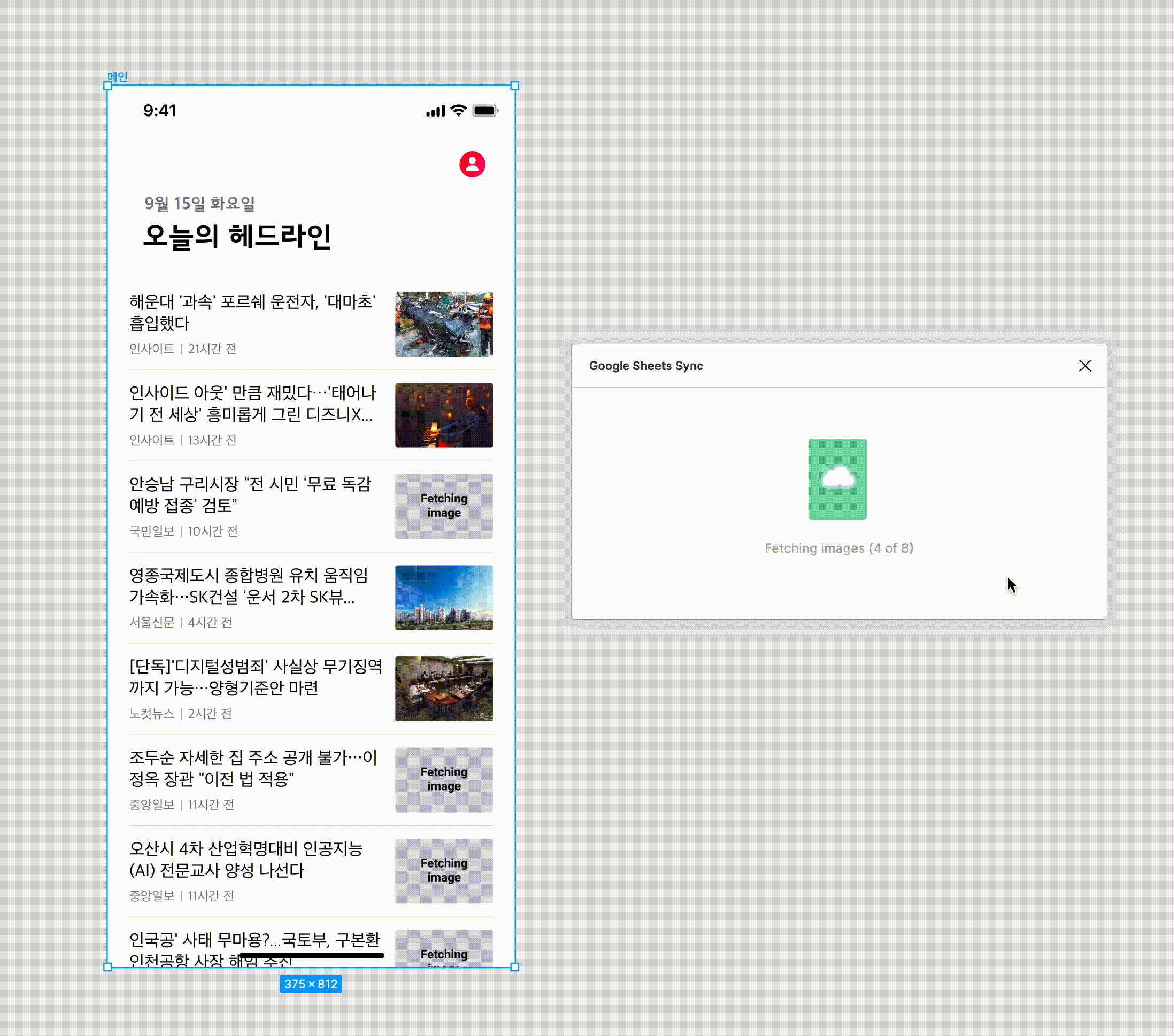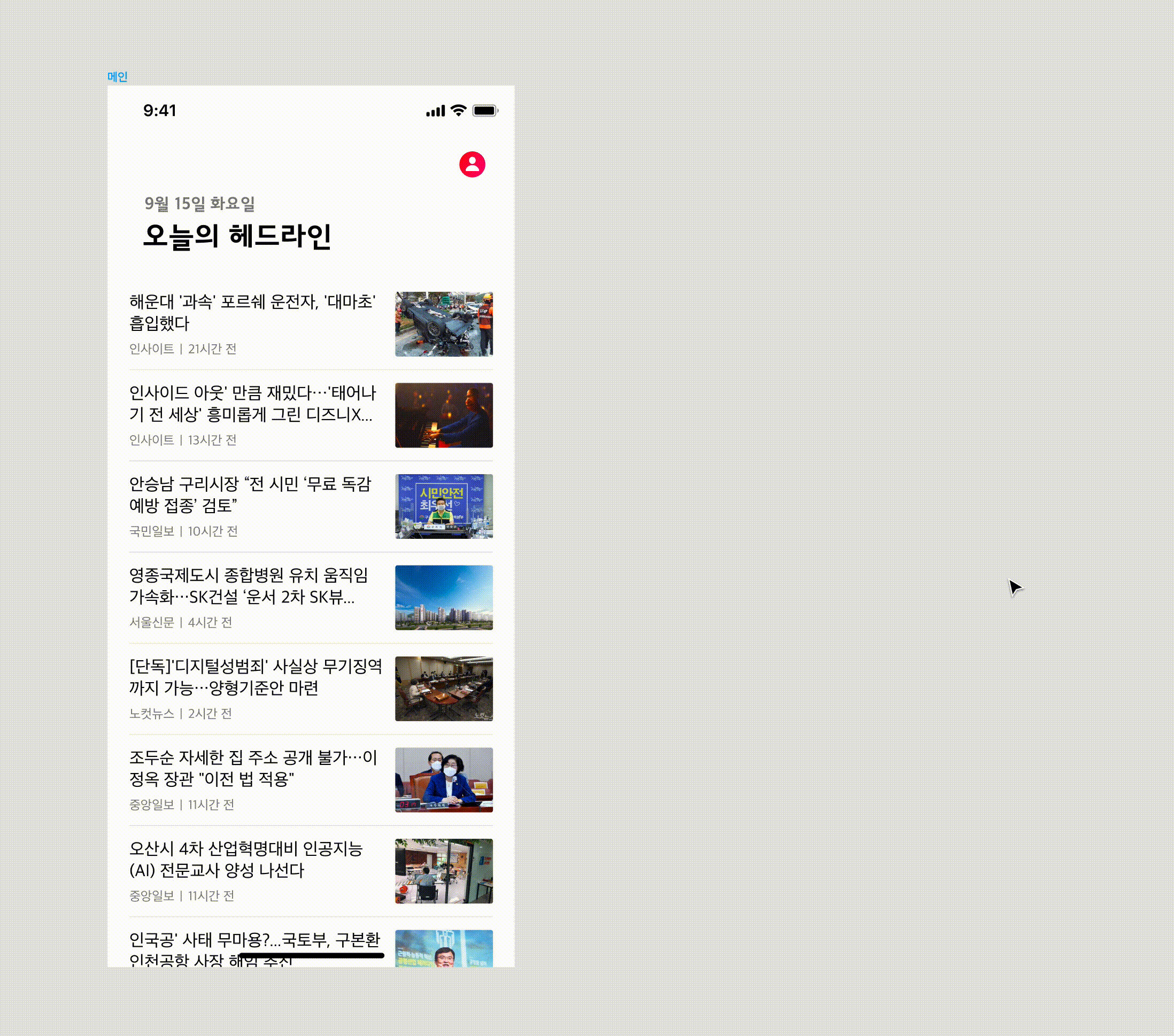
Google sheet sync 플러그인을 사용하는 모습입니다. 보시는 것 처럼 이미지 타입은 불러오는 데는 약간의 딜레이가 있긴 하지만 그래도 비교적 빠르게 데이터가 채워집니다. 하나 하나 채운다고 생각하면 비교도 안 될 만큼 많은 시간이 절약됩니다.
경험상, 컨텐츠를 채우고자 하는 프레임만 선택한 후 플러그인을 실행하는 게 정확도가 높았습니다. 그렇지 않은 경우에는 업데이트가 필요없는 프레임까지 영향을 받게 되더라구요.
Getting datas from API
실제 데이터를 활용하고 싶다고 개발자분과 이야기 나누다가 앱에서 사용중인 API를 통해 데이터를 가져와보기로 했는데요. 다만 API에 있는 모든 데이터가 필요한 것은 아니었기 때문에 사용할 몇 종류의 데이터만 가져오기 위해 파이썬을 사용했습니다. (코드 작성에 도움을 주신 Paikend 님 감사합니다!)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import requests
page = 1
while True:
url = 'site url'+str(page)
resp = requests.get(url)
results = resp.json()["results"]
for data in results:
if "photo_url" in data:
if data["photo_url"] :
print(data["photo_url"][0])
else :
print("None")
page+=1
if page ==3:
break
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import requests
page = 1
while True:
url = 'site url'+str(page)
resp = requests.get(url)
results = resp.json()["results"]
for data in results:
if "title" in data:
print(data["title"])
page+=1
if page ==3:
break
첫번째 영역은 이미지 타입 데이터를 출력하는 코드이고, 아래 영역은 텍스트 타입 데이터를 출력하는 코드입니다.
이미지 타입의 경우에는 여러개의 이미지 중 첫 번째 이미지만 출력되도록 코드를 추가했고, 이미지가 없는 경우에는 None으로 출력되도록 설정했습니다.
1
2
3
4
5
6
7
8
from random import randint
count = 0
while True:
print(str(randint(1,24))+'시간 전')
count += 1
if count >= 40:
break
time 의 경우 앱에서 사용중인 데이터 타입과 맞추기 위해 (‘랜덤’시간 전) 으로 출력되도록 설정했습니다.
데이터가 4종류 뿐이라 따로 CSV로 저장하지 않았어요.
Conclusion

개발자에게 처음 전달했던건 ‘구글 스프레드 시트’ 였습니다. 뻔뻔하게도 새 데이터로 시트를 채워달라고 했었죠.
이제는 개발자의 도움 없이도 손쉽게 데이터를 얻어오고, 시안에 채워넣을 수 있게 됐습니다. 개발자를 귀찮게 할 일이 하나 줄었으니 누이 좋고 매부 좋습니다.
한 걸음 더 나아간다면, 위의 코드들을 모두 합치고 하나의 CSV 파일로 저장할 수 있게 된다면 좋을 것 같은데요. 그건 시간날 때 해보고 잘 된다면 또 공유할게요.
읽어주셔서 감사합니다.